Statistiek vraag


zaterdag 24 juni 2017 om 12:50
Maar waarom zou je dan überhaupt de formule gebruiken als je het antwoord zo al zou weten? En ik begrijp dan niet goed wat ik verkeerd doe in mijn formule, want blijkbaar hoort er niet -2.4 uit te komen, maar -1.96. Maar ik heb de formule wel 5x opnieuw berekend.
Gemiddelde van 80, steekproefgemiddelde van 68, sigma is 20 en n = 16.
Dan krijg je (68-80)/(20/√16) = (-12)/5 = -2.4
Ik ben echt even in de war en ik heb binnenkort mijn toets, dus ik wil het graag snappen.
Gemiddelde van 80, steekproefgemiddelde van 68, sigma is 20 en n = 16.
Dan krijg je (68-80)/(20/√16) = (-12)/5 = -2.4
Ik ben echt even in de war en ik heb binnenkort mijn toets, dus ik wil het graag snappen.
zaterdag 24 juni 2017 om 13:56
De z-score geeft aan hoeveel standaardfouten het steekproefgemiddelde afligt van de mu (het gemiddelde van de verdeling onder de nulhyptothese). De standaardfout is sigma gedeeld door wortel n.
Daarom deel je (steekproefgemiddelde - mu) door de standaardfout.
Als de z-score 1.96 standaardfouten afligt van mu, hoort daar een p-waarde bij van 0.05.
In jouw voorbeeld ligt het steekproefgemiddelde meer dan 1.96 standaardfouten af van mu. Daarom hoort er een andere (lagere) p-waarde bij. In jouw voorbeeld is de kans dat het steekproefgemiddelde (of iets extremers) bij toeval waargenomen wordt als we aannemen dat de nulhypothese waar is dus kleiner dan 5 procent. En daarom verwerpen we de nulhypothese en nemen we de alternatieve hypothese aan.
Daarom deel je (steekproefgemiddelde - mu) door de standaardfout.
Als de z-score 1.96 standaardfouten afligt van mu, hoort daar een p-waarde bij van 0.05.
In jouw voorbeeld ligt het steekproefgemiddelde meer dan 1.96 standaardfouten af van mu. Daarom hoort er een andere (lagere) p-waarde bij. In jouw voorbeeld is de kans dat het steekproefgemiddelde (of iets extremers) bij toeval waargenomen wordt als we aannemen dat de nulhypothese waar is dus kleiner dan 5 procent. En daarom verwerpen we de nulhypothese en nemen we de alternatieve hypothese aan.
zaterdag 24 juni 2017 om 14:03
Begrijp je het verschil tussen alpha en de p-waarde?
De p-waarde is de kans dat de waargenomen steekproefuitkomst (of iets extremers) bij toeval voorkomt als de nulhypothese waar zou zijn. Elke keer dat je een proef herhaalt komt er dus een andere p-waarde uit.
De alpha is het significantieniveau. Dat is een grens die we vooraf vaststellen. Als de p-waarde lager is dan alfa, geloven we niet meer dat de nulhypothese waar is.
De p-waarde is de kans dat de waargenomen steekproefuitkomst (of iets extremers) bij toeval voorkomt als de nulhypothese waar zou zijn. Elke keer dat je een proef herhaalt komt er dus een andere p-waarde uit.
De alpha is het significantieniveau. Dat is een grens die we vooraf vaststellen. Als de p-waarde lager is dan alfa, geloven we niet meer dat de nulhypothese waar is.
zondag 2 juli 2017 om 22:53
Aangezien ik hier al een topic had lopen en ik een tweede openen een beetje onzin vind, hier maar even een vraag voor degene die met me mee willen denken 
Ik kreeg een vraag over een populatie- en steekproefverdeling. Het ging om een vragenlijst die afgenomen werd onder depressieve mensen. Onder populatie werden alle depressieve mensen gezien.
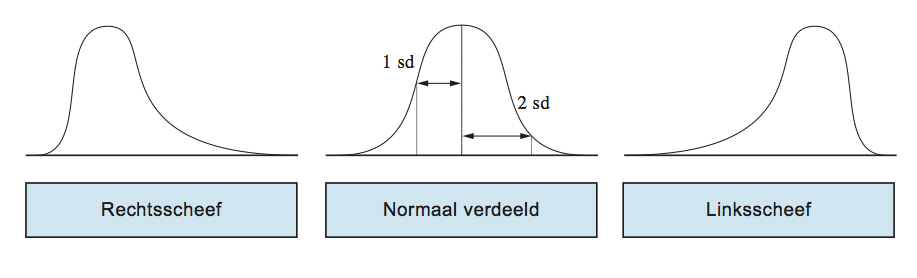
Nu was de vraag hoe de populatieverdeling er uit zou zien. Het antwoord was: scheef naar links, want veel mensen zullen hoge scores hebben. Maar naar mijn idee zou dat dan toch naar rechts moeten zijn?
Kan iemand me uitleggen waarom dat is? Ik heb me suf gegoogled, maar kom er niet uit en wil het heel graag snappen.
Ik kreeg een vraag over een populatie- en steekproefverdeling. Het ging om een vragenlijst die afgenomen werd onder depressieve mensen. Onder populatie werden alle depressieve mensen gezien.
Nu was de vraag hoe de populatieverdeling er uit zou zien. Het antwoord was: scheef naar links, want veel mensen zullen hoge scores hebben. Maar naar mijn idee zou dat dan toch naar rechts moeten zijn?
Kan iemand me uitleggen waarom dat is? Ik heb me suf gegoogled, maar kom er niet uit en wil het heel graag snappen.
maandag 3 juli 2017 om 07:57
Linksscheef houdt eigenlijk in dat de uitlopers naar links lopen, dus de piek zit aan de rechterkant. Dit houdt dus in dat minder mensen lagere scores halen en naar mate de scores hoger worden, deze vaker voorkomen.
Dit klopt dus met wat jij verwacht naar aanleiding van het feit dat mensen met depressieve klachten hoog scoren, alleen heet het linksscheef als uitlopers naar links lopen.
Hopelijk heb je hier iets aan!
Dit klopt dus met wat jij verwacht naar aanleiding van het feit dat mensen met depressieve klachten hoog scoren, alleen heet het linksscheef als uitlopers naar links lopen.
Hopelijk heb je hier iets aan!
maandag 3 juli 2017 om 10:27
Kun je dat nog iets duidelijker uitleggen? Ik zie nog niet helemaal wat je nu bedoelt.cupcakeje93 schreef: ↑03-07-2017 07:57Linksscheef houdt eigenlijk in dat de uitlopers naar links lopen, dus de piek zit aan de rechterkant. Dit houdt dus in dat minder mensen lagere scores halen en naar mate de scores hoger worden, deze vaker voorkomen.
Dit klopt dus met wat jij verwacht naar aanleiding van het feit dat mensen met depressieve klachten hoog scoren, alleen heet het linksscheef als uitlopers naar links lopen.
Hopelijk heb je hier iets aan!
maandag 3 juli 2017 om 10:27
Er stond niet meer informatie in de vraag dan wat ik nu vertel.
maandag 3 juli 2017 om 10:48
Plaatje komt van https://hulpbijonderzoek.nl/online-woor ... cheefheid/
